Open-VoiceCanvas
综合介绍
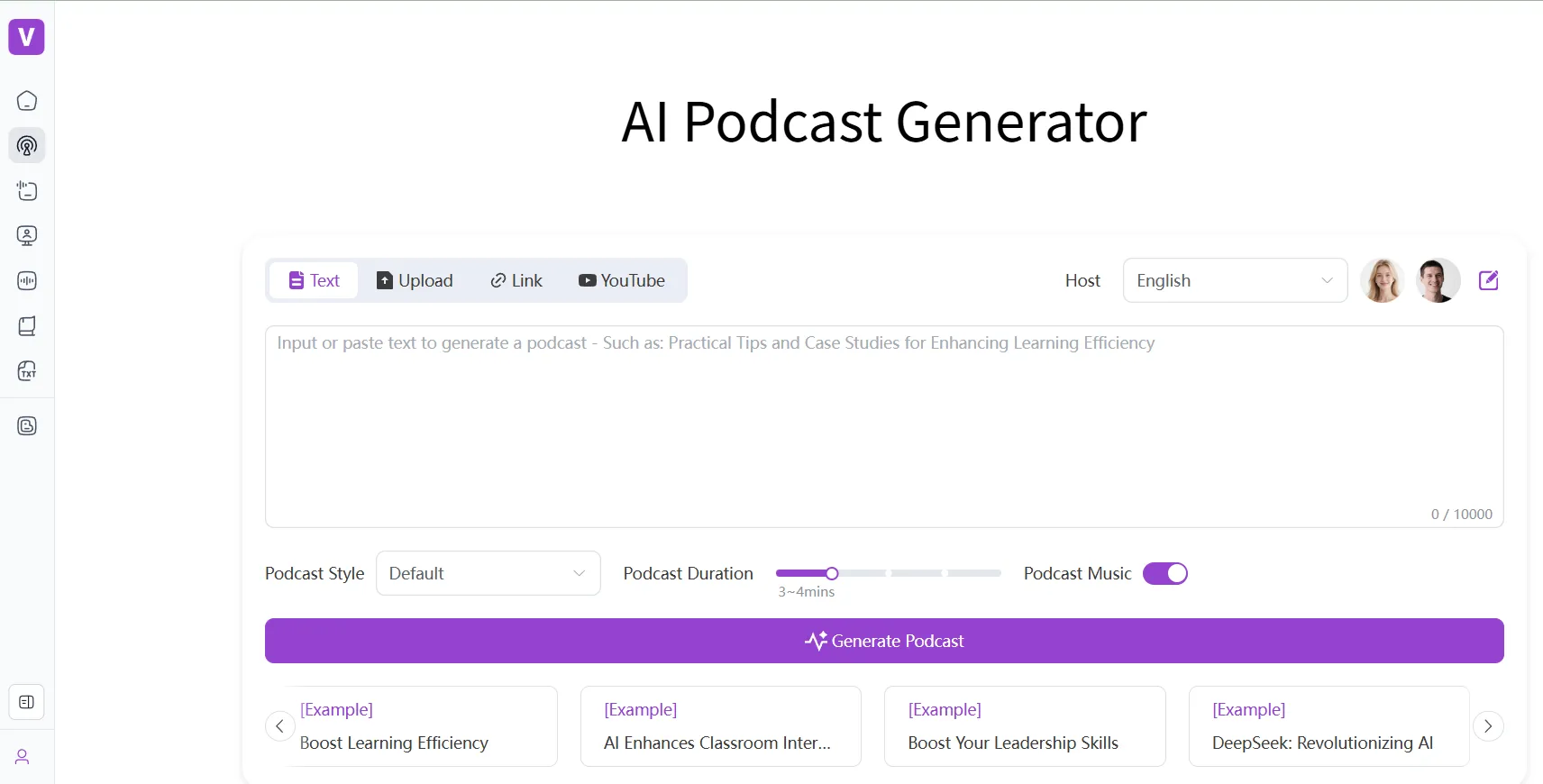
Open-VoiceCanvas,项目名称为VoiceCanvas,是一个开源的文本转语音(TTS)平台。它使用人工智能技术,为用户提供高质量的语音合成服务。该系统的核心功能是文本转换成语音和声音克隆。它整合了多种AI语音服务,包括OpenAI TTS、AWS Polly和专为中文优化的MiniMax。这使得平台不仅支持超过50种语言的文本朗读,还能克隆用户的声音,生成个性化的语音。该项目代码完全开源,方便开发者进行二次开发和部署。系统内置了完整的用户管理和订阅支付功能,支持使用Google、GitHub等第三方账号登录,并通过Stripe处理订阅支付。对于开发者来说,它提供了一个完整的商业化语音服务解决方案。
功能列表
- 多语言支持: 支持超过50种语言的文本转语音。
- 多种语音服务集成: 集成了OpenAI TTS、AWS Polly和MiniMax三种语音引擎,并支持在其中一种服务失败时自动切换到备用服务。
- 声音克隆: 用户可以上传自己的声音样本,克隆出具有个人特色的声音模型。
- 语音效果调节: 支持选择男声或女声,并可以自由调节语音的播放速度。
- 用户系统: 包含完整的用户注册、登录流程,同时支持Google和GitHub账号一键登录。
- 订阅系统: 内置Stripe支付集成,支持免费试用、按月/按年订阅以及按使用量付费等多种模式。
- 文件处理: 支持直接上传
.txt等文本文件进行转换,并可以将生成的音频文件下载到本地。 - 界面友好: 提供实时音频预览和可视化波形,并支持浅色与深色两种主题模式切换。
- 开源架构: 代码100%开源,使用Next.js、Prisma、PostgreSQL等现代化技术栈,便于开发者学习和自定义。
使用帮助
VoiceCanvas是一个功能强大的文本转语音和声音克隆平台。以下是详细的安装和使用指南,帮助您从零开始部署并使用它。
一、 系统安装与部署流程
部署VoiceCanvas需要一些基础的开发环境知识,主要是Node.js和数据库配置。
1. 克隆代码仓库首先,您需要将项目的源代码从GitHub克隆到您的本地计算机或服务器上。打开终端(命令行工具),并执行以下命令:
git clone https://github.com/ItusiAI/Open-VoiceCanvas.git
然后,进入项目目录:
cd Open-VoiceCanvas
2. 安装项目依赖项目使用npm作为包管理器。在项目根目录下,运行以下命令来安装所有必需的库和模块:
npm install
3. 配置环境变量这是最关键的一步。您需要配置API密钥和数据库连接信息,才能让系统正常工作。
首先,在项目根目录中创建一个名为.env的文件。您可以复制.env.example文件来创建:
cp .env.example .env
接下来,用文本编辑器打开.env文件,并填入以下必需的配置信息。这些信息需要您提前在相应服务平台注册并获取。
必需配置:
- 语音服务API密钥:
OPENAI_API_KEY: 您的OpenAI API密钥。MINIMAX_API_KEY: 您的MiniMax API密钥。MINIMAX_GROUP_ID: 您的MiniMax组ID。NEXT_PUBLIC_AWS_REGION: AWS区域,例如us-east-1。NEXT_PUBLIC_AWS_ACCESS_KEY_ID: 您的AWS访问密钥ID。NEXT_PUBLIC_AWS_SECRET_ACCESS_KEY: 您的AWS秘密访问密钥。
- 数据库URL:
DATABASE_URL: 您的PostgreSQL数据库连接字符串。项目推荐使用Neon这种Serverless Postgres数据库,您也可以使用其他PostgreSQL服务商。
- 支付系统(Stripe):
STRIPE_SECRET_KEY: 您的Stripe秘密密钥。NEXT_PUBLIC_STRIPE_PUBLISHABLE_KEY: 您的Stripe可发布密钥。STRIPE_WEBHOOK_SECRET: 用于处理支付事件的Stripe Webhook密钥。
- 认证系统(NextAuth.js):
NEXTAUTH_URL: 您的应用部署网址,在本地开发时通常是http://localhost:3000。NEXTAUTH_SECRET: 一个用于加密会话的随机字符串,您可以自己生成。
可选配置(第三方登录):
GITHUB_ID: 您的GitHub OAuth应用客户端ID。GITHUB_SECRET: 您的GitHub OAuth应用客户端密钥。GOOGLE_ID: 您的Google OAuth应用客户端ID。GOOGLE_SECRET: 您的Google OAuth应用客户端密钥。
4. 运行数据库迁移当环境变量配置完成后,您需要初始化数据库结构。Prisma ORM使得这个过程非常简单。运行以下命令,它会根据prisma/schema.prisma文件中的定义创建所有数据表:
npx prisma migrate dev
5. 启动开发服务器现在,一切准备就绪。运行以下命令来启动本地开发服务器:
npm run dev
启动成功后,您可以在浏览器中访问 http://localhost:3000,即可看到VoiceCanvas的界面。
二、 主要功能操作指南
1. 文本转语音(TTS)这是平台的核心功能。
- 输入文本:在主界面的文本框中,输入或粘贴您想要转换为语音的文字。您也可以直接点击上传按钮,选择一个文本文件。
- 选择语言和声音:在文本框下方,您可以看到语言选择和声音选择的下拉菜单。根据您的文本内容选择对应的语言,然后选择一个您喜欢的声音(如
alloy,echo等)。 - 调整语速:通过拖动语速滑块,可以加快或减慢生成语音的语速。
- 生成和预览:点击“生成语音”按钮。系统会调用AI引擎进行转换,完成后会自动在下方的播放器中播放生成的音频。您也可以看到音频的波形图。
- 下载音频:如果您对生成的语音满意,可以点击下载按钮,将音频文件保存为MP3格式。
2. 声音克隆声音克隆允许您创建自己独特的声音模型。
- 进入克隆页面:登录后,在用户菜单或导航栏中找到“声音克隆”功能入口。
- 上传音频样本:您需要按照页面的提示,上传一段或多段清晰的个人录音作为声音样本。为了保证克隆效果,请确保录音背景噪音小,人声清晰。
- 开始克隆:上传完成后,点击“开始克隆”按钮。系统后台会开始训练您的声音模型,这个过程可能需要一些时间。
- 使用克隆声音:克隆完成后,您新创建的声音会出现在文本转语音页面的声音选择列表中。选择它,就可以用您自己的声音来朗读任何文本了。
3. 管理订阅
- 查看套餐:在“订阅”或“账户设置”页面,您可以看到不同等级的订阅套餐,包括免费套餐、包月套餐等。
- 升级套餐:选择您想要的套餐,点击升级,页面会跳转到Stripe支付界面完成付款。成功后,您的账户字符配额和功能权限会自动更新。
应用场景
- 内容创作为视频、播客或有声读物快速生成旁白。创作者无需自己录音,只需输入文稿,即可获得高质量的画外音,并能保持声音风格的一致性。
- 个性化客户服务企业可以克隆品牌代言人或特定员工的声音,用于自动电话应答系统(IVR)或智能客服,为用户提供更具亲和力和品牌辨识度的服务体验。
- 语言学习辅助语言学习者可以输入任意文本,并选择不同语言和口音的语音进行朗读,用于练习听力和模仿发音。平台支持超过50种语言,使其成为一个强大的学习工具。
- 开发者集成开发者可以将VoiceCanvas部署为私有服务,并通过其API(需自行封装)为自己的应用程序提供语音合成功能,例如在新闻App中添加“收听文章”的功能。
QA
- 这个项目是完全免费的吗?项目本身的代码是100%开源且免费的,您可以自由下载、修改和部署。但是,它依赖的第三方语音服务(如OpenAI TTS, AWS Polly)是收费的,您需要为这些服务的使用量向相应的提供商支付费用。
- 我不是程序员,可以安装和使用吗?安装部署过程需要一定的技术背景,例如使用命令行、配置环境变量等。如果您不熟悉这些操作,可能会遇到困难。对于非技术用户,更适合使用已经部署好的成品网站,而不是自行安装。
- 声音克隆对上传的音频有什么要求?为了达到最佳的克隆效果,建议上传清晰、无背景噪音、时长足够(通常建议几分钟以上)的单人录音。上传的音频质量直接决定了克隆声音的相似度和自然度。
- 支持哪些语言?中文效果如何?该平台支持超过50种语言。对于中文,它专门集成了MiniMax语音服务,该服务对中文进行了优化,因此生成的中文语音在流畅度和自然度上表现通常会很好。